LLM Observability: Tracing, Logging, and Debugging AI Applications
Introduction
When a traditional web application breaks, you check the logs. You see the exact HTTP request that arrived, the database query that ran, the exception that was thrown, and the stack trace that points to the offending line of code. You can reproduce the bug, understand its cause, and fix it systematically.
LLM applications do not work this way. When a user complains that the chatbot gave a wrong answer, checking conventional logs tells you almost nothing, just that an API call was made and a response came back. You cannot see what the exact prompt was, what documents were retrieved from the vector database, whether the model received malformed context, or why it chose to hallucinate a particular fact.
This is the problem that LLM observability solves. Observability means instrumenting your application so you can see exactly what happened at every stage of every request: what prompt was sent, what context was retrieved, how many tokens were consumed, how long each part took, and what the model produced. Without this visibility, debugging is guesswork and quality improvement is near impossible.
This article explains what LLM observability is, which components you need, how traces work, and which tools are available for production systems.
Problem Statement
Traditional application monitoring tracks infrastructure-level signals: latency, throughput, error rates, CPU and memory utilisation. These metrics are necessary but not sufficient for LLM applications. They tell you that something is wrong, requests are slow, errors are rising, but not why.
The failure modes unique to LLM applications are fundamentally different from those of conventional software. A chatbot can return a 200 HTTP status code while simultaneously giving a completely wrong, misleading, or harmful answer. There is no exception, no stack trace, and no error log. The application "worked" from an infrastructure perspective, but the user received bad output.
Diagnosing these failures requires answering questions that traditional monitoring cannot address. What exactly was in the prompt? Did the retrieval step return relevant documents or off-topic noise? Did the model receive the complete conversation history or was context truncated? Was a particular hallucination triggered by a specific retrieved document? Without logging this information at the time of the request, these questions are unanswerable, and the same failure will recur indefinitely.
Core Concepts and Terminology
| Term | Definition | Why It Matters |
|---|---|---|
| Observability | The ability to understand the internal state of a system from its external outputs, especially through structured instrumentation | Without it, production LLM failures cannot be diagnosed or reproduced |
| Trace | A structured record of everything that happened during a single request, from start to finish, broken into individual spans | The fundamental unit of LLM observability, a trace is the "receipt" for a request |
| Span | A single step within a trace, representing one operation such as embedding a query, searching the vector database, or calling the LLM | Spans show exactly how long each stage took and what inputs and outputs it produced |
| TTFT (Time to First Token) | The time elapsed from when the request is sent until the first token of the model's response is received | The most important latency metric for interactive applications, dominates perceived responsiveness |
| Token Usage | The number of input and output tokens consumed by a model call | Directly controls API cost; sudden increases signal prompt bugs or retrieval issues |
| Cost Tracking | Recording the dollar cost of each model call and aggregating by user, session, endpoint, and time period | LLM API costs can spike unexpectedly due to prompt bugs, cost monitoring is essential for budget control |
| Prompt Logging | Storing the complete final prompt sent to the model for each request | Required to reproduce failures and understand why the model produced a particular output |
| PII (Personally Identifiable Information) | Data that can identify an individual person, such as names, email addresses, phone numbers, or location data | User queries frequently contain PII; full prompt logging must include PII redaction from the start |
| LangSmith | A managed observability platform built specifically for LangChain applications | Provides automatic tracing with minimal setup for LangChain-based systems |
| LangFuse | An open-source LLM observability platform that supports any Python LLM application and can be self-hosted | The right choice when data privacy requirements prevent sending logs to a third-party service |
| OpenTelemetry | A vendor-neutral open standard for distributed tracing that works across programming languages and infrastructure | Useful when you want to integrate LLM observability into an existing enterprise tracing stack |
How It Works
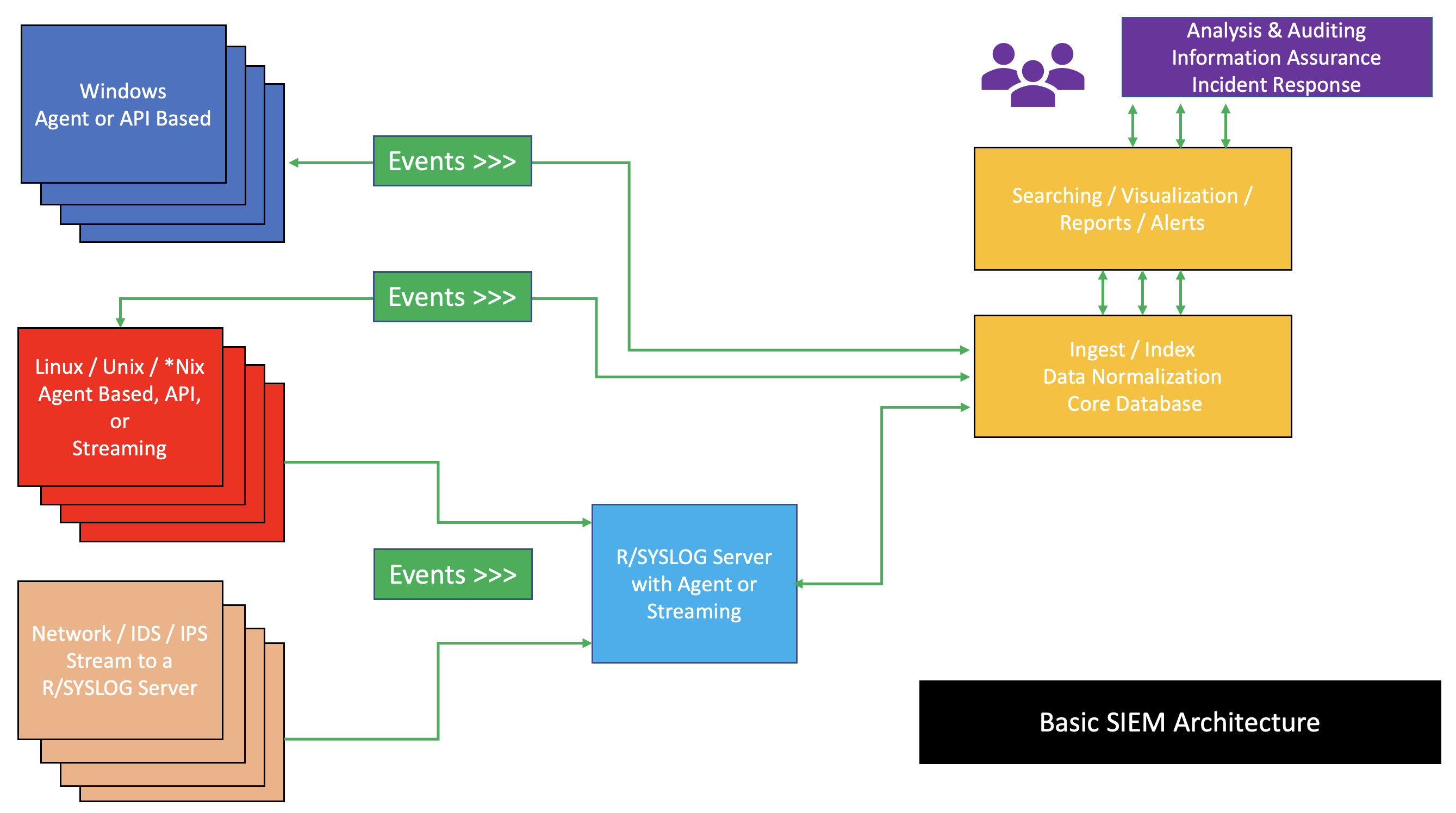
LLM observability is built around traces, structured records that capture everything that happened during a single user request. Think of a trace as a detailed audit trail, similar to a shipping tracking record that shows every location a package passed through, the time at each stop, and whether anything went wrong along the way.
- Assign a unique trace ID to every incoming request. This ID propagates through every stage of the pipeline, linking all logs and measurements back to the original request. When a user reports a problem, you look up their trace ID and see the complete picture.
- Create a span for each pipeline stage. As the request flows through your application, receiving the query, generating an embedding, searching the vector database, assembling the prompt, calling the model, post-processing the response, each step creates a span. A span records the stage name, start time, end time, inputs, outputs, and any metadata like token counts or document IDs.
- Capture the complete prompt before every model call. This is the most important log entry in an LLM system. The assembled prompt, system instructions, conversation history, retrieved context, and user message, determines the model's output entirely. Without logging it, you cannot understand why the model said what it said.
- Record token usage and cost per model call. Attach the input token count, output token count, and computed API cost to each model call span. This enables cost allocation by user or endpoint and early detection of prompt bloat.
- Ship spans to a centralised trace store. Completed spans are sent asynchronously, so they do not add latency to the response path, to a trace storage system such as LangSmith, LangFuse, or a backend compatible with OpenTelemetry.
- Collect user feedback signals and link them to traces. When a user rates a response as helpful or not helpful, record that signal alongside the trace ID. This creates a labelled dataset of good and bad model outputs that you can use to identify systematic failure patterns.
- Set up automated alerts on key metrics. Define thresholds for daily cost, error rate, and average latency. When any metric crosses a threshold, alert on-call engineers immediately. LLM failures often have unusual signatures, a prompt bug that inflates token counts will appear as a cost spike before it appears as a user complaint.
Practical Example
A company runs a RAG-based customer support assistant. A user reports that the bot gave incorrect information about the cancellation policy. The support team submits a ticket.
Without observability, the investigation begins with guesswork. Was the policy document in the database? Was it retrieved for this query? Was the retrieved text correct? Did the model misread it, or was the wrong document retrieved?
With proper traces in place, the investigation takes minutes. The engineer searches the trace store for the user's session identifier and finds the exact trace for that request. The trace shows four spans: the query embedding took 85 milliseconds, the vector search returned five documents in 110 milliseconds, the LLM call took 1,340 milliseconds, and post-processing took 15 milliseconds. The prompt span shows the exact text that was assembled and sent to the model, including all five retrieved documents.
Examining the retrieved documents, the engineer sees the problem immediately. The vector search returned a document about the cancellation policy for a legacy product tier that was discontinued two years ago. The document was never removed from the vector store when the policy changed. The model faithfully summarised that outdated document and presented the old policy as current.
The fix is to remove the outdated document from the index and add a metadata filter to exclude documents with a deprecated flag. Without the trace, this root cause would have taken days to find, if it was found at all.
Advantages
- Transforms debugging from guesswork into systematic investigation. With a full trace for every request, a reported failure becomes a known and reproducible state. You examine the trace, identify which span produced the wrong output, and fix the root cause, the same process as debugging a traditional program with a good stack trace.
- Enables cost accountability and early budget protection. Tracking API cost at the span level lets you attribute spending to specific users, endpoints, and prompt patterns. When a prompt bug triples the average token count, the cost monitoring alerts fire before the monthly bill arrives.
- Makes retrieval failures visible. In a RAG system, the most common source of bad model outputs is bad retrieval. Traces that show exactly which documents were retrieved, along with their relevance scores, make it immediately obvious when retrieval is the culprit rather than the model.
- Supports prompt iteration with quality tracking. When you change a prompt or update the retrieval strategy, traces let you compare the outputs before and after the change on a consistent set of test cases. You can measure whether the change helped or hurt before it reaches all users.
- User feedback linked to traces creates a self-improving quality loop. Thumbs-up and thumbs-down signals linked to specific traces create a labelled dataset of model successes and failures. This dataset can be used to identify the most impactful failure patterns and prioritise improvements.
Limitations and Trade-offs
- Full prompt logging captures sensitive user data. User queries frequently contain names, account numbers, health information, and other PII. Storing raw prompts without redaction creates significant privacy and compliance risk. Building PII detection into the logging layer is not optional, it is a regulatory requirement in many jurisdictions.
- High-volume logging generates substantial storage costs. Full prompt strings can be thousands of characters long. At scale, storing a complete trace for every request adds up quickly. Sampling strategies, logging 100% of failures and errors, 10% of successful requests, are necessary for cost management at high traffic volumes.
- Instrumentation adds code complexity. Adding tracing to every stage of a pipeline requires either framework-level instrumentation (which LangSmith and LangFuse provide for supported frameworks) or manual span creation in custom code. This adds development overhead that must be budgeted for from the start of a project.
- Trace stores can become a performance bottleneck if logging is synchronous. If spans are written to disk or a database synchronously inside the request path, every request pays the logging overhead. All trace shipping must be asynchronous and non-blocking.
- Third-party observability platforms send your prompts and responses to external services. LangSmith and LangFuse cloud-hosted options process your trace data on their infrastructure. For applications handling confidential or regulated data, this may not be acceptable. LangFuse's self-hosted option addresses this, but adds operational overhead.
Common Mistakes
- Logging without alerting. Logs that no one looks at are useless. The value of observability is in surfacing problems proactively. Set up automated alerts for cost spikes, elevated error rates, unusual latency, and dropped retrieval quality scores. Logs are infrastructure; alerts are what make that infrastructure actionable.
- Ignoring PII in logged prompts. Teams often add prompt logging quickly during development and forget to add redaction before real users start interacting with the system. Once sensitive data is logged, the remediation, identifying and purging affected records, is far more expensive than building the redaction in from the start.
- Over-logging intermediate states. Logging every variable and intermediate computation in the pipeline generates massive data volumes and makes it harder to find the logs that actually matter. Log the inputs and outputs of each stage, not every internal variable. Use sampling for high-traffic paths.
- Treating observability as a post-launch concern. Many teams ship a first version without any observability and plan to "add it later." In practice, retrofitting observability into a running production system is much harder than building it in from the beginning. Treat observability as a day-one requirement, not a future enhancement.
- Not linking user feedback to specific traces. Without connecting user ratings to the exact request that produced a given response, feedback data is nearly useless for debugging. A thumbs-down with no trace ID tells you that users are unhappy; a thumbs-down linked to a trace tells you exactly which retrieved document, which prompt structure, and which model output caused the dissatisfaction.
Best Practices
- Treat observability as a day-one infrastructure requirement, not a post-launch enhancement. The cost of retrofitting is always higher than the cost of building it in from the start.
- Implement PII redaction in your logging layer before any real user data touches it. Use a dedicated PII detection library or regex rules to sanitise prompts and responses before they are stored.
- Use asynchronous, non-blocking trace shipping for all span data. Logging must never add latency to the response path.
- Log the complete assembled prompt for every model call. This single log entry is the most valuable piece of data for debugging model output failures.
- Set automated alerts for at minimum: daily API cost, sustained error rate above a threshold, and latency spikes. Do not rely on manual log review to detect production issues.
- Link user feedback signals (ratings, corrections, explicit reports) to trace IDs so you can inspect the exact request context that produced bad outputs.
- Sample traces at a rate appropriate for your traffic volume. Log 100% of errors and failures, and sample a fraction of successful requests to contain storage costs.
- Implement a data retention policy. Delete traces older than a defined period, 90 days is a common choice, unless they are required for compliance purposes.
Comparison: LLM Observability Tools
| Tool | Type | Best For | Pricing | Self-Hosted Option | Key Strength |
|---|---|---|---|---|---|
| LangSmith | Managed SaaS | LangChain applications | Paid with free tier | No | Auto-tracing with two environment variables; built-in dataset management and evaluation |
| LangFuse | Open-source | Any LLM application; privacy-sensitive deployments | Free (self-hosted) or cloud SaaS | Yes | Framework-agnostic; prompt versioning; full data control via self-hosting |
| Helicone | Managed SaaS | OpenAI-based applications | Freemium | No | Proxy-based setup requiring no code changes; cost tracking and rate limiting built in |
| OpenTelemetry | Open standard framework | Custom integrations; enterprise teams with existing tracing infrastructure | Free | Yes | Vendor-neutral; works with any backend including Jaeger, Datadog, and Grafana Tempo |
| Datadog LLM Observability | Managed SaaS | Enterprise teams already using Datadog for infrastructure monitoring | Paid | No | Full-stack integration, LLM traces sit alongside infrastructure and APM data in one platform |
| Custom logging layer | DIY | Teams with strict data residency requirements or unusual pipeline architectures | Operational cost only | N/A, fully owned | Complete control over what is logged, how it is stored, and who can access it |
Frequently Asked Questions
Do I need observability if I am using a managed LLM API like OpenAI or Anthropic?
Yes. Managed APIs provide basic usage statistics, token counts and costs at the account level, but they do not give you visibility into your application's pipeline. You cannot see the exact prompts your application sends, the context retrieved in a RAG system, the conversation history assembled per request, or the correlation between retrieval quality and model output. All of that visibility requires instrumentation in your own application layer.
What is the difference between logging and tracing?
Logging records individual events, a model call happened, an error occurred, a document was retrieved. Tracing connects all the events that belong to a single user request into a coherent, ordered record. A trace groups all the logs for one request together with timing information, so you can see not just what happened but in what order, how long each step took, and how the stages relate to each other. Tracing is what makes debugging tractable; raw logs alone are a pile of disconnected events.
How do I choose between LangSmith and LangFuse?
If you are building with LangChain and data privacy allows sending prompts to a third-party service, LangSmith is the path of least resistance, automatic tracing with minimal setup. If you need to self-host for data privacy or regulatory compliance, or if your application does not use LangChain, LangFuse is the better choice. LangFuse works with any Python LLM application and provides equivalent functionality with the option to keep all data within your own infrastructure.
How long should I retain trace data?
A common policy is 90 days for standard traces and one year for traces linked to compliance-relevant events or user complaints. The right retention period depends on your regulatory requirements and the cost of storage. Define and enforce the policy before real user data arrives, retroactive data purging is expensive and error-prone.
What should I do if observability shows that costs are spiking unexpectedly?
First, identify whether the cost increase is driven by input tokens, output tokens, or both. A spike in input tokens usually points to a prompt bug: a loop appending context incorrectly, retrieval returning too many documents, or conversation history that is not being truncated. A spike in output tokens usually points to a max-tokens setting that is too generous for a specific endpoint, or a model that is generating excessively verbose responses for a class of queries. The trace data will show which specific requests are driving the cost increase, pointing directly to the root cause.
References
- LangSmith Documentation. LLM Observability Platform
- Langfuse Documentation. Open-Source LLM Engineering Platform
- OpenTelemetry Documentation. Vendor-Neutral Observability Standard
- Breck, E., Cai, S., Nielsen, E., Salib, M., and Sculley, D. (2017). The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction. IEEE Big Data 2017.
- Kleppmann, M. (2017). Designing Data-Intensive Applications. O'Reilly Media.
Key Takeaways
- Traditional infrastructure monitoring cannot diagnose LLM-specific failures. You need traces that record the exact prompt, retrieved documents, token counts, and model output at every stage of every request.
- A trace is the fundamental unit of LLM observability. It connects all the events for a single user request into an ordered, timed record that makes failures reproducible and debuggable.
- LangSmith is the easiest starting point for LangChain applications, automatic tracing requires only two environment variables. LangFuse is the right choice when data privacy requires self-hosting or when your application does not use LangChain.
- Monitor cost, latency, token usage, retrieval quality, and error rates. Set automated alerts on all five so anomalies surface before users notice them.
- Always sanitise logs to protect user privacy. Treat trace data with the same care as any other sensitive production data, and implement PII redaction before any real user traffic reaches your system.
- Observability is a day-one infrastructure investment, not a post-launch enhancement. The cost of retrofitting it into a running system is always higher than building it in from the start.

